End-to-end ILER
End-to-end ILER methods directly map diagnosed student state or unmastered concepts into exercise recommendations.
DRER
End-to-end ILER
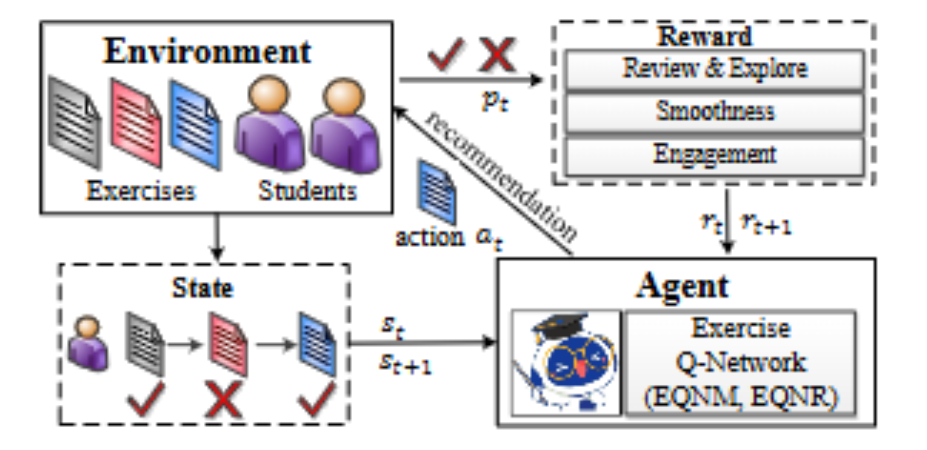
DRER is a deep reinforcement learning framework for adaptive exercise recommendation. It uses Exercise Q-Networks to capture students' exercising states and histories, and optimizes multi-objective rewards.
State ModelingRepresents exercising states and historical interaction signals.
Exercise Q-NetworkScores candidate exercises through a reinforcement learning formulation.
Multi-objective RewardJointly considers review and exploration, smoothness, and engagement.
Original paper: Exploring Multi-Objective Exercise Recommendations in Online Education Systems
AKTRec
End-to-end ILER
AKTRec adapts the AKT knowledge tracing model for exercise recommendation. AKT uses self-attentive encoders and a monotonic attention mechanism to model past exercise history; AKTRec then identifies unmastered knowledge concepts and recommends exercises covering these gaps.
Attentive KT EncoderModels the student's historical interactions with attention.
Knowledge Gap DiagnosisFinds knowledge concepts that remain insufficiently mastered.
Exercise RetrievalMaps weak concepts to corresponding exercises.
Original paper: Context-Aware Attentive Knowledge Tracing
SimpleKTRec
End-to-end ILER
SimpleKTRec adapts SimpleKT, a lightweight attention-based knowledge tracing framework. It combines exercise embeddings with their associated knowledge concepts and uses dot-product attention to extract temporal knowledge states for recommendation.
Concept-aware EmbeddingRepresents exercises through their related knowledge concepts.
Temporal AttentionExtracts evolving knowledge states efficiently.
Gap-based RecommendationRecommends exercises linked to unmastered concepts.
Original paper: simpleKT: A Simple But Tough-To-Beat Baseline for Knowledge Tracing
MMER
End-to-end ILER
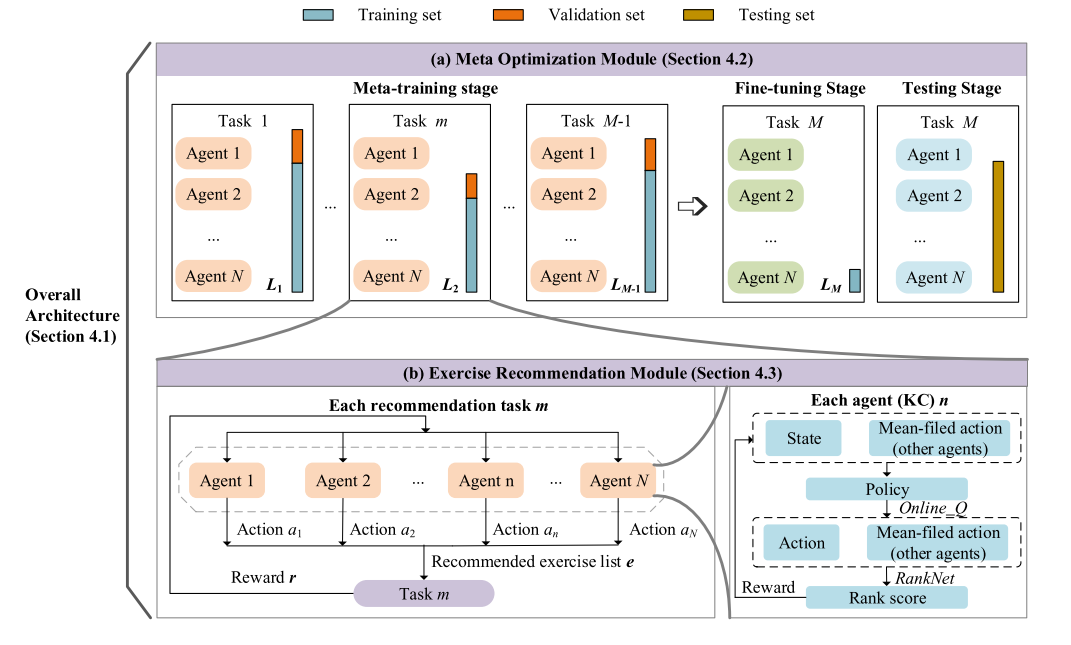
MMER is a meta multi-agent reinforcement learning framework for exercise recommendation. Each knowledge concept is treated as an agent, enabling cooperative and competitive interactions among concepts and adaptation to new student groups.
Concept AgentsModels each KC as an agent in a multi-agent setting.
Meta-trainingSupports quick adaptation with few-shot student data.
Recommendation PolicyCoordinates KC-level signals to select exercises.
Original paper: Meta Multi-Agent Exercise Recommendation: A Game Application Perspective
Two-stage ILER
Two-stage ILER methods separate candidate generation from filtering, re-ranking, or set-level optimization.
KCP-ER
Two-stage ILER
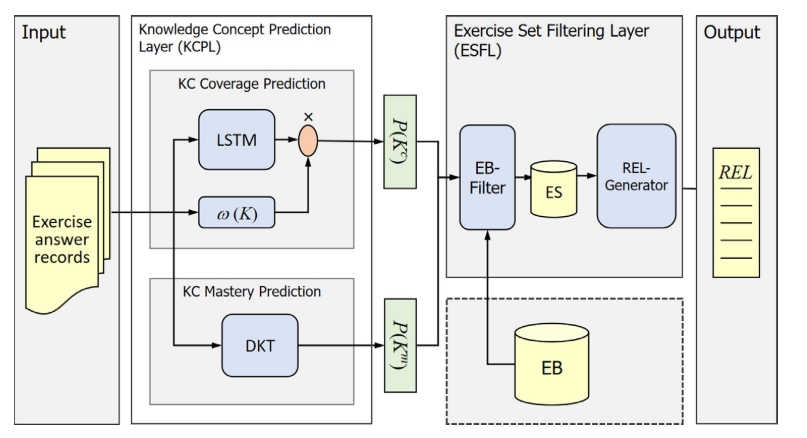
KCP-ER uses a Knowledge Concept Prediction Layer and an Exercise Set Filtering Layer. It predicts concept coverage and mastery, filters suitable exercises, and generates a diversified recommendation list.
KC PredictionPredicts coverage and mastery of knowledge concepts.
Exercise FilteringSelects exercises by difficulty and novelty constraints.
List GenerationUses simulated annealing to improve diversity.
Original paper: Exercise Recommendation Based on Knowledge Concept Prediction
KG4Ex
Two-stage ILER
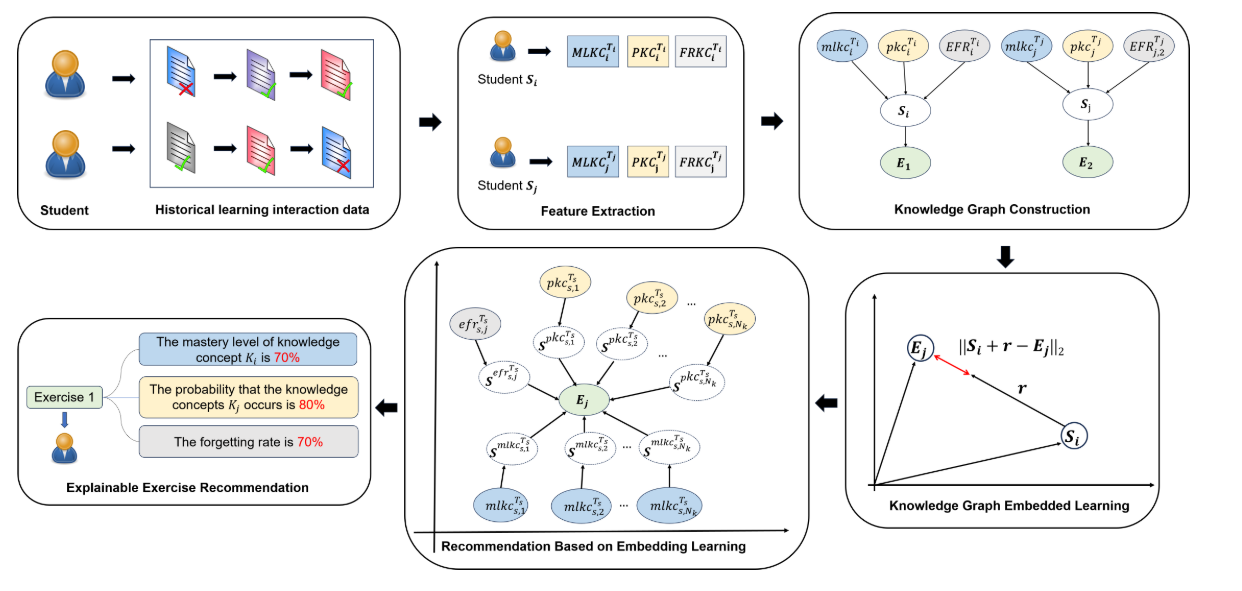
KG4Ex is a two-stage exercise recommendation method with feature extraction and knowledge graph-based recommendation. It learns relationships among students, exercises, and knowledge concepts to produce explainable recommendations.
Feature ExtractionComputes mastery, future concept probability, and forgetting-related signals.
Knowledge GraphBuilds structured relations among students, exercises, and KCs.
Explainable RankingUses graph embeddings to recommend exercises with reasons.
Original paper: KG4Ex: An Explainable Knowledge Graph-Based Approach for Exercise Recommendation
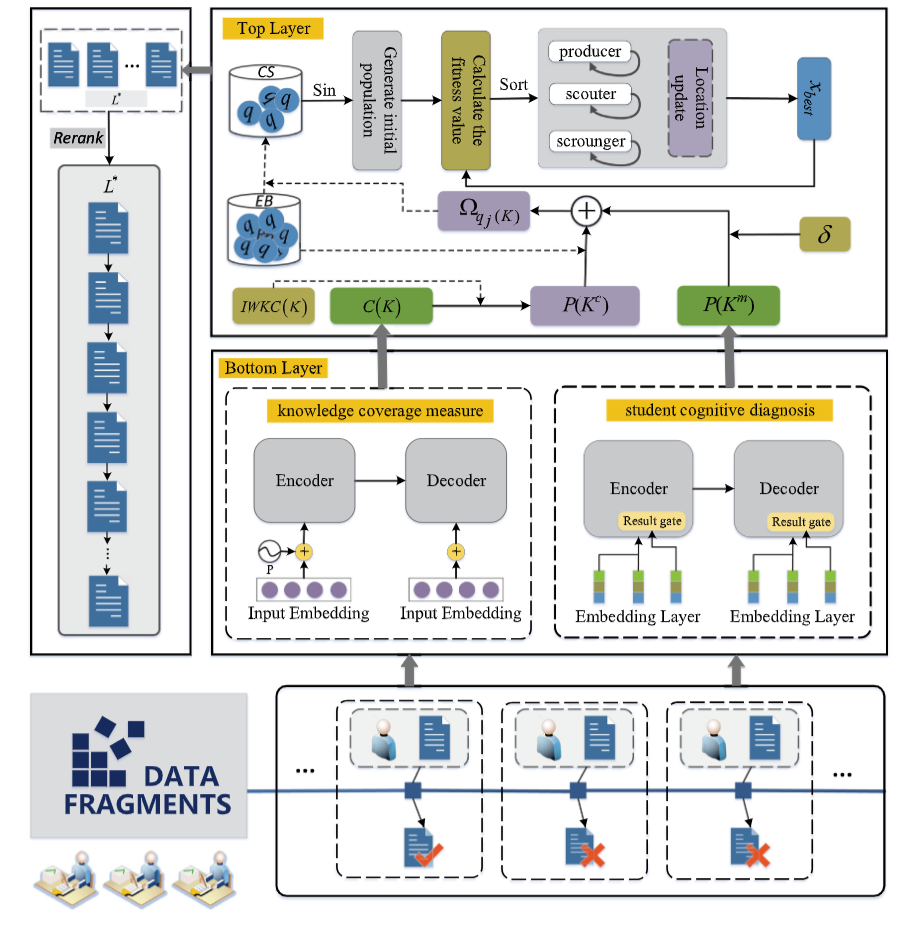
MulOER
Two-stage ILER
MulOER-SAN adopts a two-layer multi-objective framework. The bottom layer traces mastery and predicts concept coverage with self-attention, while the top layer filters candidate exercises and optimizes diversity with smooth difficulty progression.
Self-attention LayerPredicts KC coverage and traces student mastery.
Candidate FilteringConstructs a candidate subset for recommendation.
Multi-objective SearchOptimizes diversity while controlling difficulty smoothness.
Original paper: MulOER-SAN: 2-Layer Multi-Objective Framework for Exercise Recommendation with Self-Attention Networks
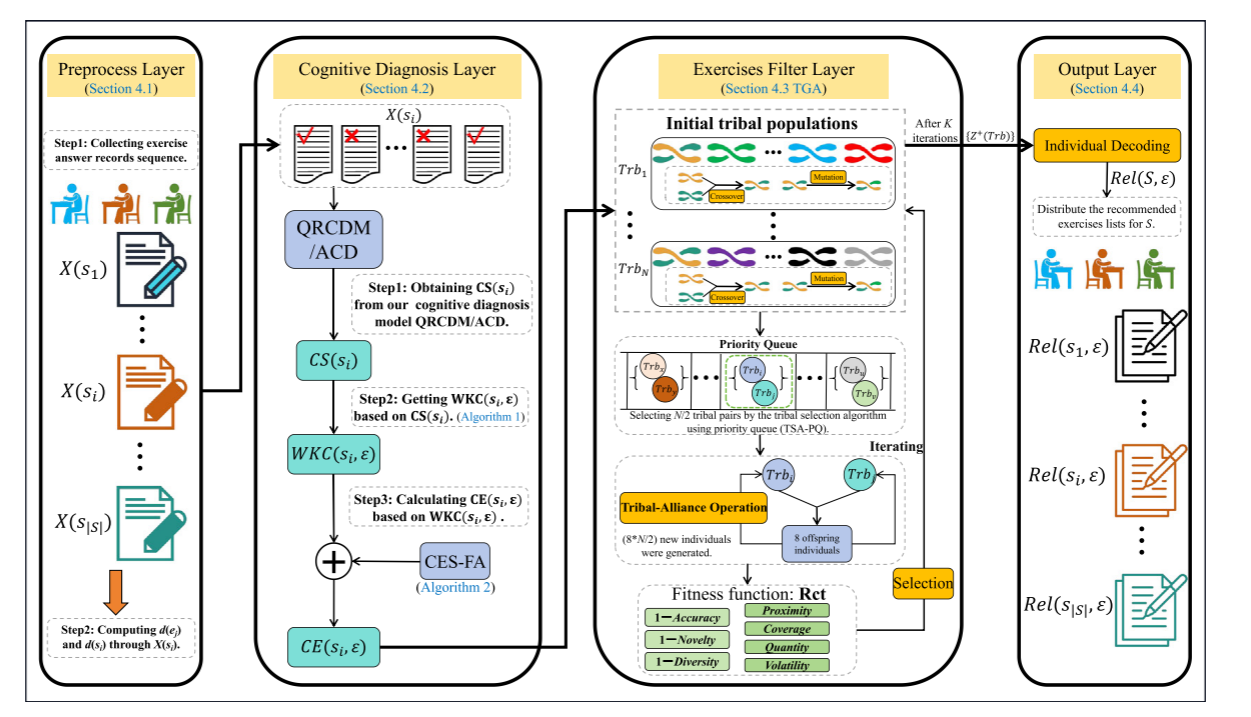
ER-TGA
Two-stage ILER
ER-TGA combines cognitive diagnosis with a tribal-alliance genetic algorithm. It identifies weak knowledge components, builds candidate exercises, and selects an exercise subset by minimizing multi-objective recommendation cost.
Cognitive DiagnosisIdentifies weak knowledge components and supports cold-start scenarios.
Candidate Exercise SetBuilds candidate exercises aligned with knowledge gaps.
TGA OptimizationBalances accuracy, novelty, diversity, proximity, coverage, quantity, and volatility.
Original paper: Comprehensive Exercise Recommendation with Practicality, Generalizability, and Versatility in AI-Driven Education
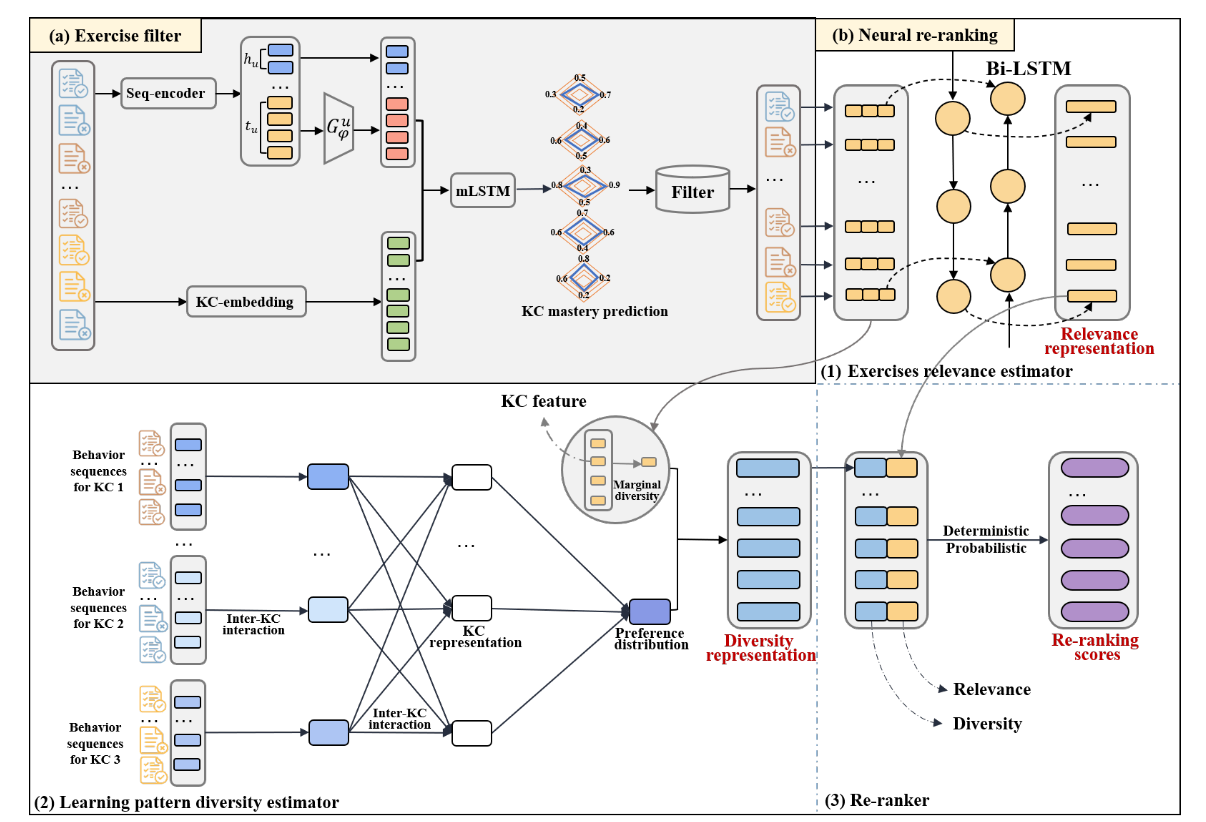
NR4DER
Two-stage ILER
NR4DER contains an exercise filter module and a neural re-ranking module. It predicts mastery, builds suitable candidates, enhances inactive student representations, and re-ranks exercises for relevance and diversity.
Exercise FilterPredicts mastery and constructs difficulty-appropriate candidates.
Student EnhancerImproves representation for inactive students.
Neural Re-rankingIntegrates relevance and learning pattern diversity.
Original paper: NR4DER: Neural Re-ranking for Diversified Exercise Recommendation
Step-by-step PLER
Step-by-step PLER treats learning path generation as sequential decision-making and updates decisions along the path.
AC
Step-by-step PLER
AC applies the classical Actor-Critic framework to step-by-step learning path recommendation. The critic estimates the value of the current student state, and the actor selects the next exercise to optimize learning outcomes.
ActorSelects the next exercise according to the current policy.
CriticEstimates expected value for the current student state.
TD UpdateUses temporal-difference learning to update policy and value estimates.
Original paper: Actor-Critic Algorithms
DQN
Step-by-step PLER
DQN adapts Deep Q-Network style reinforcement learning to step-by-step recommendation. The agent estimates action values for possible next exercises and updates them through Q-learning with experience replay.
State ObservationRepresents the current learning state before choosing the next action.
Q-value EstimationScores candidate next exercises as actions.
Experience ReplayStabilizes off-policy updates by replaying past transitions.
Original paper: Human-Level Control Through Deep Reinforcement Learning
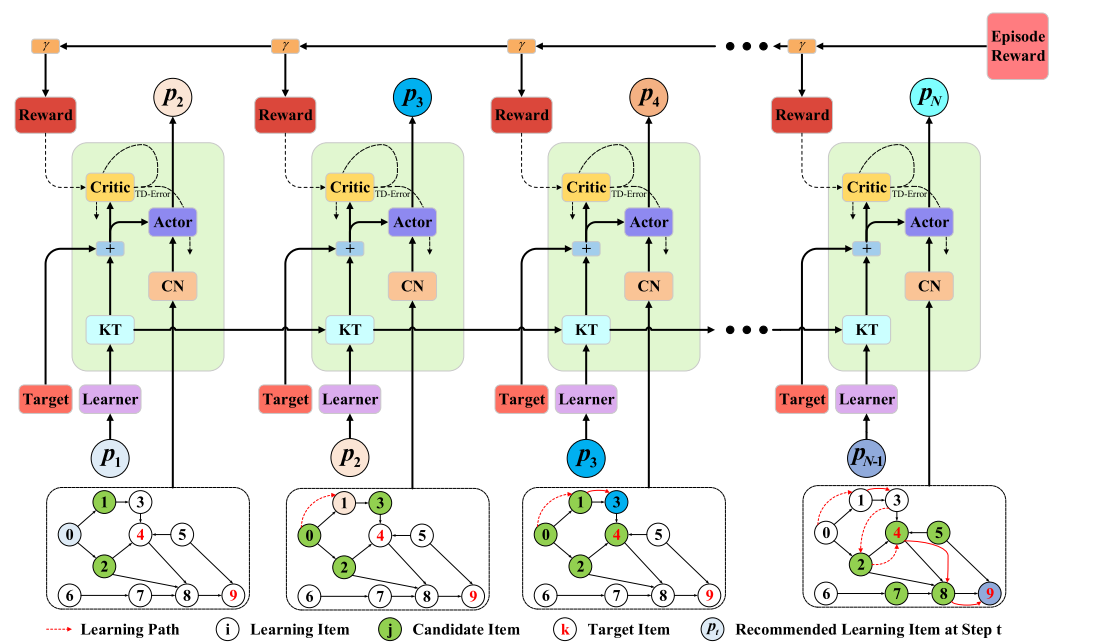
CSEAL
Step-by-step PLER
CSEAL models learning path recommendation as a Markov Decision Process. It combines knowledge tracing, cognitive navigation, and an actor-critic recommender to generate exercises sequentially.
Knowledge TracingEstimates evolving student mastery levels.
Cognitive NavigationSelects candidate items through prerequisite graph constraints.
Actor-Critic RecommenderChooses exercises while reducing search space.
Original paper: Exploiting Cognitive Structure for Adaptive Learning
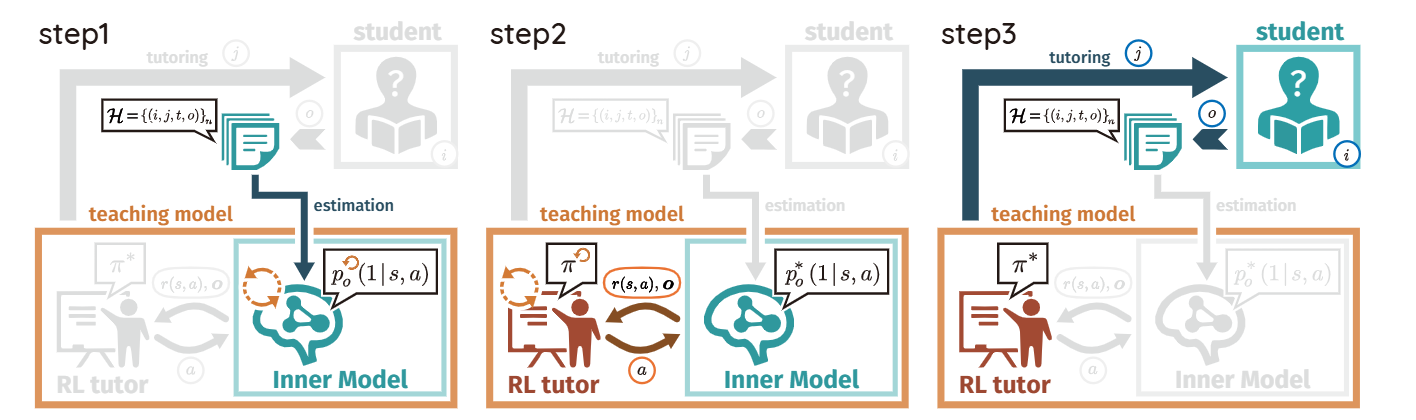
RLTutor
Step-by-step PLER
RLTutor models adaptive tutoring as a step-by-step sequential decision problem. An inner model estimates student knowledge state, and a PPO-based reinforcement learning agent optimizes the teaching strategy.
Inner ModelEstimates current student knowledge state with temporal memory dynamics.
Virtual StudentSupports learning policies with fewer real student interactions.
PPO AgentOptimizes the next exercise recommendation strategy.
Original paper: RLTutor: Reinforcement Learning Based Adaptive Tutoring System by Modeling Virtual Student with Fewer Interactions
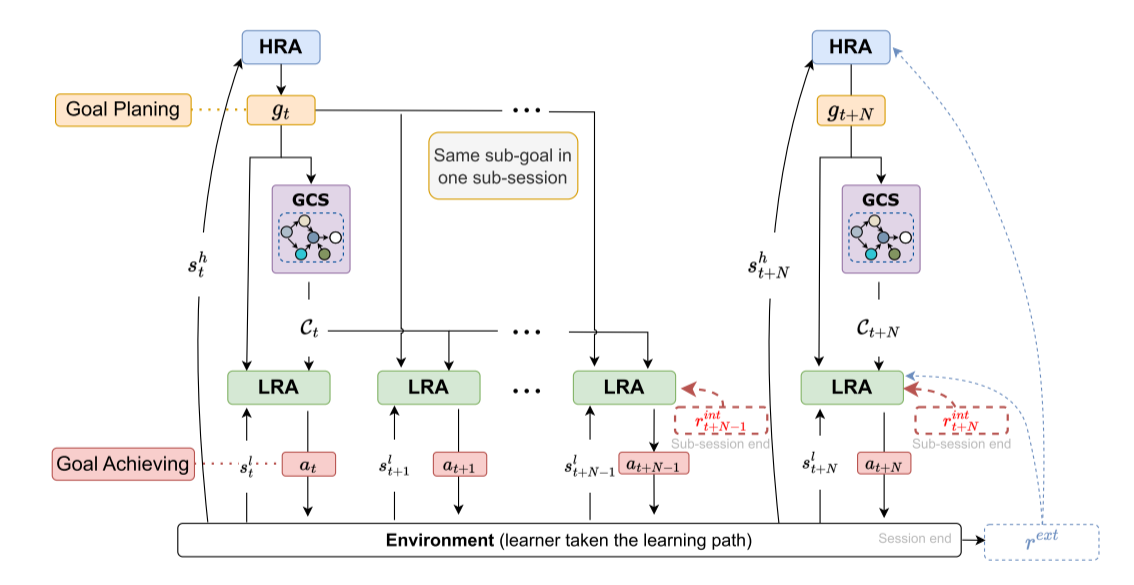
GEHRL
Step-by-step PLER
GEHRL uses hierarchical reinforcement learning for goal-oriented learning path recommendation. A high-level agent selects sub-goals, while a low-level agent recommends learning items to achieve each sub-goal.
High-level AgentSelects sub-goals aligned with the target objective.
Low-level AgentRecommends items sequentially for each sub-goal.
Graph Candidate SelectorConstrains actions to goal-related exercises.
Original paper: Graph Enhanced Hierarchical Reinforcement Learning for Goal-Oriented Learning Path Recommendation
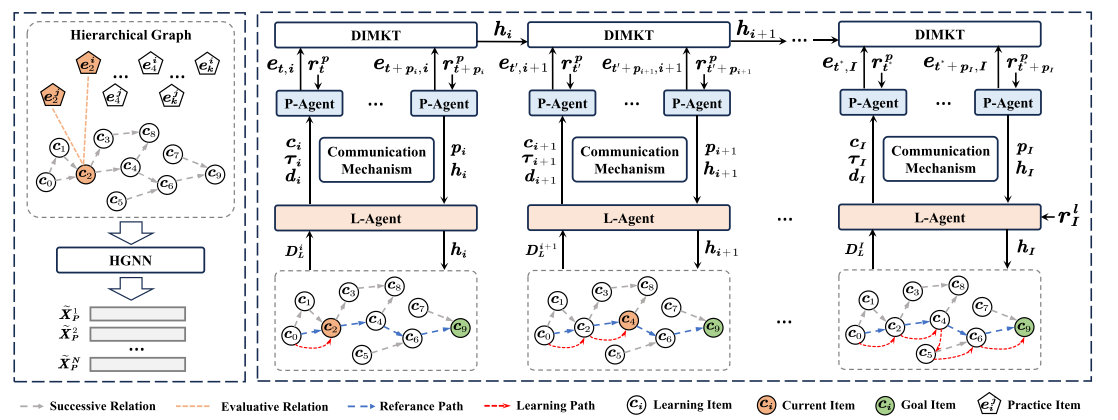
DLPR
Step-by-step PLER
DLPR addresses learning path recommendation as a dynamic sequential decision problem. It uses a Difficulty-driven Hierarchical Reinforcement Learning framework with an L-Agent and a P-Agent, together with knowledge state estimation.
L-AgentSelects learning items at the high level.
P-AgentChooses associated practice items at the low level.
DIMKT State EstimatorTracks evolving knowledge and difficulty signals.
Original paper: Item-Difficulty-Aware Learning Path Recommendation: From a Real Walking Perspective
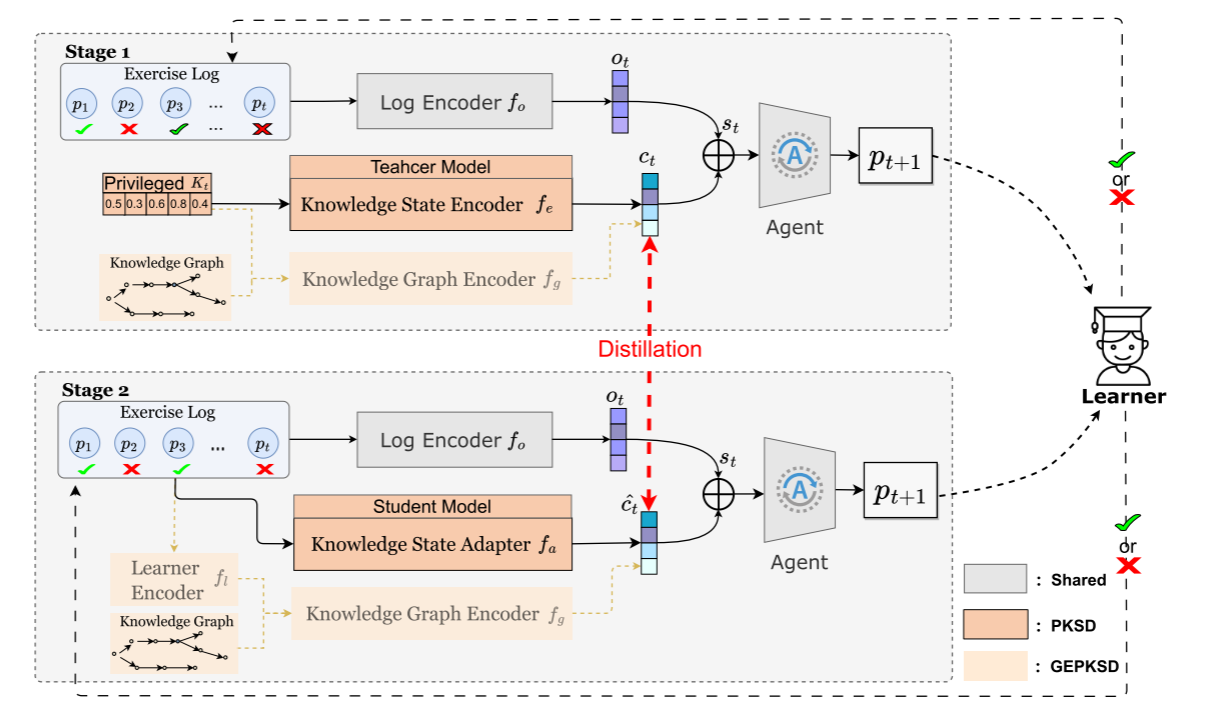
PKSD
Step-by-step PLER
PKSD introduces privileged knowledge state distillation for reinforcement learning-based educational path recommendation. It uses simulator-derived knowledge state as privileged information during training and estimates latent knowledge state during inference.
Privileged State EncoderLearns from simulator-derived knowledge state during training.
Knowledge State AdapterEstimates latent state from regular exercise logs at inference time.
RL Path AgentGenerates personalized and structured learning paths.
Original paper: Privileged Knowledge State Distillation for Reinforcement Learning-Based Educational Path Recommendation
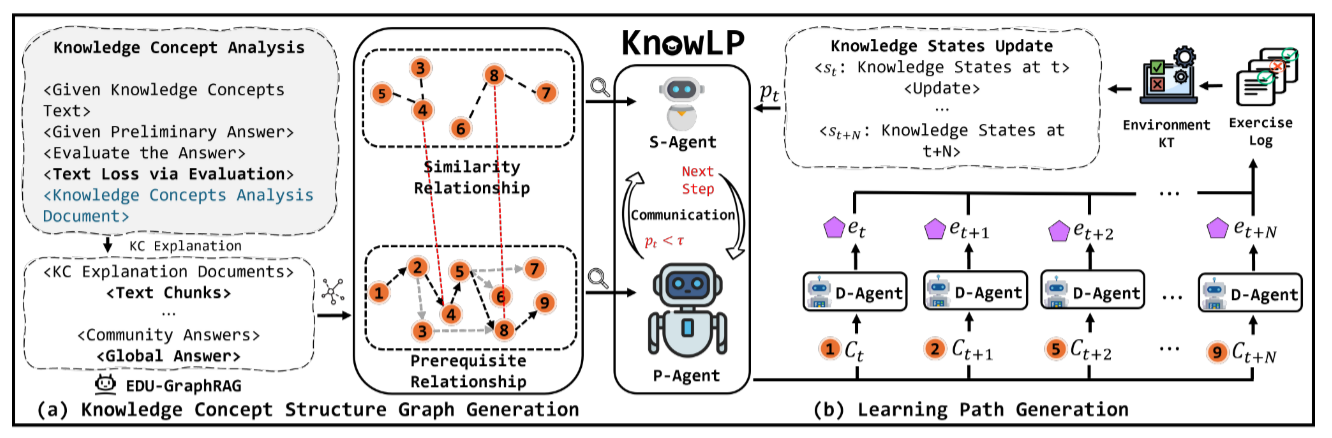
KnowLP
Step-by-step PLER
KnowLP constructs personalized learning paths with step-by-step reinforcement learning guided by dual knowledge structure graphs. It uses specialized agents to address prerequisite, similarity, and difficulty factors.
Dual Knowledge GraphsCapture prerequisite and similarity relations among concepts.
Specialized AgentsSelect concepts and exercises according to prerequisite, similarity, and difficulty signals.
Knowledge TracingTracks mastery and difficulty to adapt the generated path.
Original paper: GraphRAG-Induced Dual Knowledge Structure Graphs for Personalized Learning Path Recommendation